[TOC]
流水线最基础的部分是 “step”。基本上, step告诉 Jenkins 要做什么,以及作为声明式(Declarative)和脚本化(Scripted)流水线语法的基本构建块。
Declarative Pipeline-声明管道
有效的Declarative Pipeline必须包含在一个pipeline块内,例如
1 | pipeline { |
Declarative Pipeline中有效的基本语句和表达式遵循与Groovy语法相同的规则 ,但有以下例外:
- Pipeline的顶层必须是块(block),其实就是
pipeline { } - 没有分号作为语句分隔符。每个声明必须在自己的一行
- 块只能包含章节, 指令,步骤Sections, Directives, Steps或赋值语句
- 属性引用语句被视为无参数方法调用。所以例如,input被视为input()
第一点: 就是声明指定的代码块
第二点:分号写了也是多余的。Groovy代码还可以写分号,Jenkins Pipeline代码就不需要,每行只写一个声明语句块或者调用方法语句
第三点:只能包含Sections, Directives, Steps或者赋值语句
第四点:没懂,懂了再回来补充
Sections-章节/节段
Declarative Pipeline 代码中的Sections指的是必须包含一个或者多个指令或者步骤的代码区域块。Sections不是一个关键字或者指令,只是一个逻辑概念。
agent指令-代理
agent部分指定整个Pipeline或特 定阶段将在Jenkins环境中执行的位置,具体取决于该agent 部分的放置位置。该部分必须在pipeline块内的顶层定义 ,但阶段级使用是可选的
简单来说,agent部分主要作用就是告诉Jenkins,选择那台节点机器去执行Pipeline代码;这个指令是必须要有的,也就在你顶层pipeline {…}的下一层,必须要有一个agent{…}
agent这个指令对应的多个可选参数。
这里注意一点,在具体某一个stage {…}里面也可以使用agent指令。这种用法不多,一般我们在顶层使用agent,这样,接下来的全部stage都在一个agent机器下执行代码。
为了支持Pipeline作者可能拥有的各种用例,该agent部分支持几种不同类型的参数。这些参数可以应用于pipeline块的顶层,也可以应用在每个stage指令内。
参数1:any
作用:在任何可用的代理上执行Pipeline或stage
1 | pipeline { |
上面这种是最简单的,如果你Jenkins平台环境只有一个master,那么这种写法就最省事情
参数2:none
作用:当在pipeline块的顶层应用时,将不会为整个Pipeline运行分配全局代理,并且每个stage部分将需要包含其自己的agent部分,就像上面说的在具体某一个stage {…}里面也可以使用agent指令
1 | pipeline { |
参数3:label
作用:使用提供的标签在Jenkins环境中可用的代理机器上执行Pipeline或stage内执行
1 | pipeline { |
参数4:node
作用:和上面label功能类似,但是node运行其他选项,例如customWorkspace
1 | pipeline { |
post指令
post部分定义将在Pipeline运行或阶段结束时运行的操作
post部分定义一个或多个steps,这些阶段根Pipeline或stage的完成情况而运行,post 支持以下 post-condition 块中的其中之一: always, changed, failure, success, unstable, 和 aborted
简单来说,post可以放在顶层,也就是和agent{…}同级,也可以放在stage里面。一般放顶层的比较多。而且pipeline代码中post代码块不是必须的,使用post的场景基本上执行完一个构建,进行发送消息通知,例如构建失败会发邮件通知
简单示例:
1 | pipeline { |
post条件的基本用法
在post代码块区域,支持多种条件指令,这些指令有always,changed,failure,success,unstable,和aborted。下面分别来介绍这些条件的基本用法。
条件1:always
作用:无论Pipeline运行的完成状态如何都会执行这段代码
1 | pipeline { |
这个always场景,很容易想到的场景就是,事后清理环境。例如测试完了,对数据库进行恢复操作,恢复到测试之前的环境。
条件2:changed
作用:只有当前Pipeline运行的状态与先前完成的Pipeline的状态不同时,才能触发运行。
1 | pipeline { |
这个场景,大部分是写发邮件状态。例如,你最近几次构建都是成功,突然变成不是成功状态,里面就触发发邮件通知。当然,使用changed这个指令没success和failure要频率高
条件3:failure
作用:只有当前Pipeline运行的状态与先前完成的Pipeline的状态不同时,才能触发运行。
1 | pipeline { |
这个failure条件一般来说,百分百会写到Pipeline代码中,内容无非就是发邮件通知,或者发微信群,钉钉机器人,还有国外的slack聊天群组等。
stages和steps指令
stages被外层的
pipeline { }包裹,内部包含多个stage每个stage代码块内包含多个steps { },一个stage下至少有一个steps { },一般也就是一个steps { }
我们可以在一个steps下写调用一个或者几个方法,也就是两三行代码。具体的代码实现,可以放在别的包里面
stages下可以包含多个stage, 在一个Declarative Pipeline脚本中,只允许出现一次stages
以后我们大部分的pipeline代码都在每一个stage里面的steps下,如下示例
1 | pipeline { |
上面println是Groovy的语法,就是一个打印语句。不管以后pipeline代码有多么复杂,都是以这个为基础骨架,例如添加一些try catch语句还有其他的指令。
stage指令
该stage指令在该stages部分中,应包含步骤部分,可选agent部分或其他特定于阶段的指令。实际上,Pipeline完成的所有实际工作都将包含在一个或多个stage指令中。
stage一定是在stages{…}里面,一个pipeline{…}中至少有一个stages{…}和一个stage{…}.这里多说一句,一个stage{…}中至少有一个steps{…}。stage{…}还有一个特点就是,里面有一个强制的字符串参数,例如下面的”Example”,这个字符串参数就是描述这个stage是干嘛的,这个字符串参数是不支持变量的,只能你自己取名一个描述字段。
1 | pipeline { |
environment指令
environment指令定义一个键-值,该键-值对将被定义为所有步骤的环境变量,或者是特定于阶段的步骤, 这取决于 environment 指令在流水线内的位置。
解释一下什么意思,environment{…}, 大括号里面写一些键值对,也就是定义一些变量并赋值,这些变量就是环境变量。环境变量的作用范围,取决你environment{…}所写的位置,你可以写在顶层环境变量,让所有的stage下的step共享这些变量,也可以单独定义在某一个stage下,只能供这个stage去调用变量,其他的stage不能共享这些变量。
一般来说,我们基本上上定义全局环境变量,如果是局部环境变量,我们直接用def关键字声明就可以,没必要放environment{…}里面
1 | Pipeline { |
options指令
该options指令允许在Pipeline本身内配置Pipeline专用选项,Pipeline提供了许多这些选项,例如buildDiscarder,但它们也可能由插件提供,例如 timestamps。
一个pipeline{…}内只运行出现一次options{…}, 下面看一个下这个retry的使用。
1 | pipeline { |
上面的整个pipeline{…}, 如果在jenkins上job执行失败,会继续执行,如果再遇到失败,继续执行一次,总共执行三次
把options{…}放在顶层里,也可以放在具体的某一个stage下,意味这这个stage下所有代码,如果遇到失败,最多执行三次。
parameters指令
parameters是参数的意思,parameters指令提供用户在触发Pipeline时应提供的参数列表,这些用户指定的参数的值通过该params对象可用于Pipeline步骤。
我们很多人听过参数化构建(Build with Parameters),也可能知道如何在一个jenkins job上,通过UI创建不同的参数,例如有字符串参数,布尔选择参数,下拉多选参数等。这些参数即可以通过UI点击创建,也可以通过pipeline代码去写出来。我们先来看看了解有那些具体参数类型,然后挑选几个,分别用UI和代码方式去实现创建这些参数。
字符串参数
就是定义一个字符串参数,用户可以在Jenkins UI上输入字符串,常见使用这个参数的场景有,用户名,收件人邮箱,文件网络路径,主机名称的或者url等
1 | pipeline { |
布尔值参数
就是定义一个布尔类型参数,用户可以在Jenkins UI上选择是还是否,选择是表示代码会执行这部分,如果选择否,会跳过这部分。一般需要使用布尔值的场景有,执行一些特定集成的脚本或则工作,或者事后清除环境,例如清楚Jenkins的workspace这样的动作。
1 | pipeline { |
文本参数
文本(text)的参数就是支持写很多行的字符串,这个变量我好像没有使用过,例如想给发送一段欢迎的消息,你可以采用text的参数。
1 | pipeline { |
上面的\n表示换行,上面写了三行的text
选择参数
选择(choice)的参数就是支持用户从多个选择项中,选择一个值用来表示这个变量的值。工作中常用的场景,有选择服务器类型,选择版本号等。
1 | pipeline { |
文件参数
文件(file)参数就是在Jenkins 参数化构建UI上提供一个文件路径的输入框,Jenkins会自动去你提供的网络路径去查找并下载。一般伴随着还有你需要在Pipleline代码中写解析文件。也有这样场景,这个构建job就是把一个war包部署到服务器上特定位置,你可以使用这个文件参数。
1 | pipeline { |
密码参数
密码(password)参数就是在Jenkins 参数化构建UI提供一个密文密码输入框,例如,我需要在一些linux机器上做自动化操作,需要提供机器的用户名和密码,由于密码涉及安全问题,一般都采用暗文显示,这个时候你就不能用string类型参数,就需要使用password参数类型
1 | pipeline { |
web ui方式
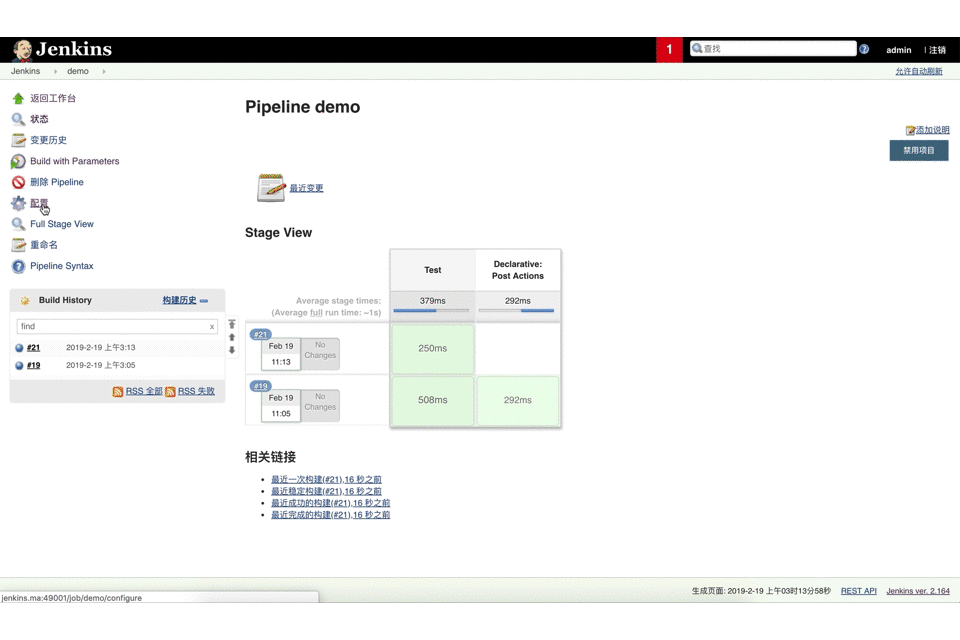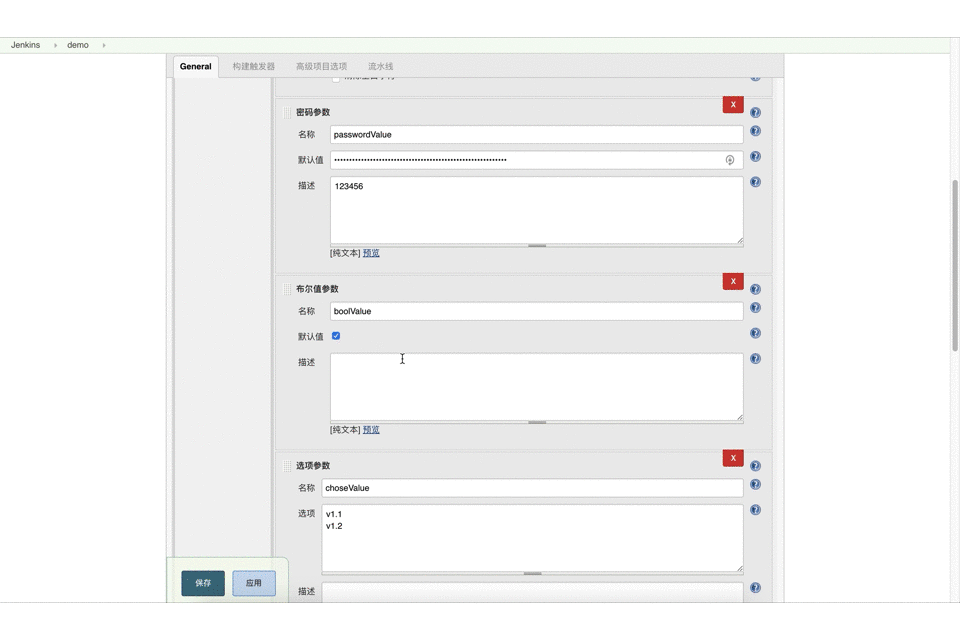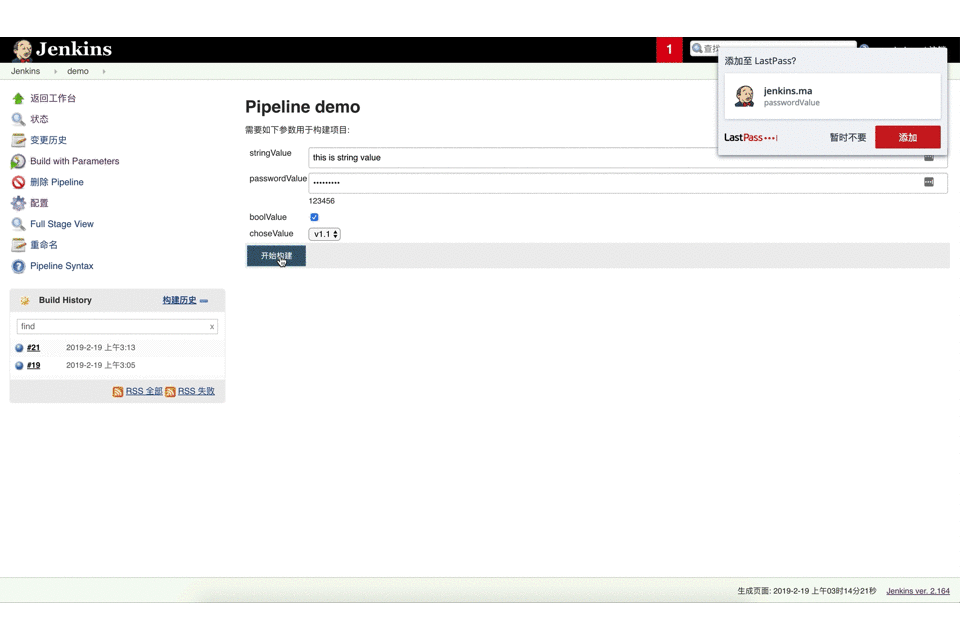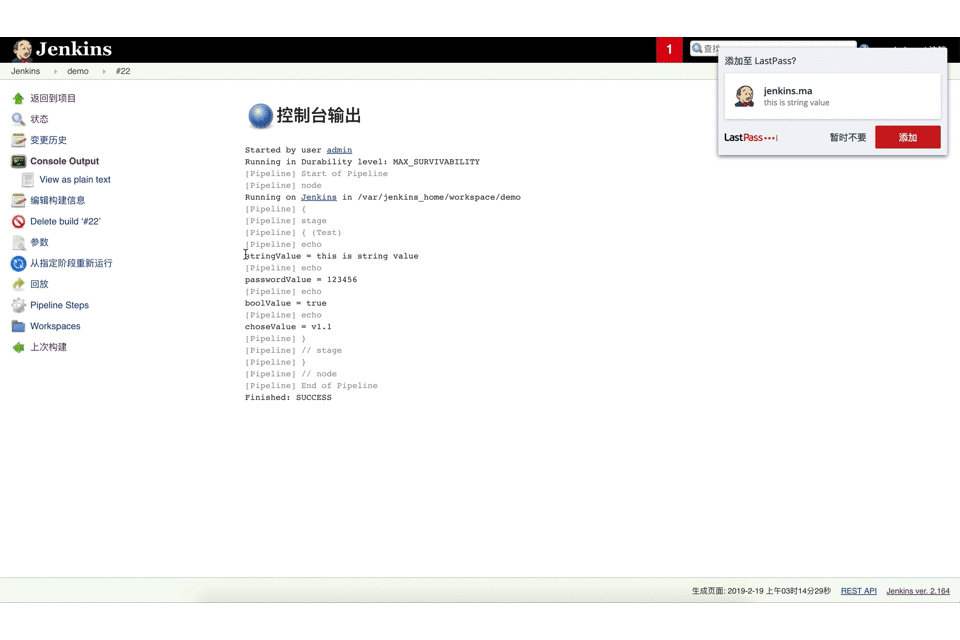
1 | pipeline { |
triggers指令
- 该triggers指令定义了Pipeline应重新触发的自动化方式。对于与源代码集成的Pipeline,如GitHub或BitBucket,triggers可能不需要基于webhook的集成可能已经存在
- 目前有三个可用的触发器是cron和pollSCM 和 upstream
- 在一个pipeline{…}代码中,只运行出现一次triggers{…},而且这个指令不是必须存在的。
- triggers是触发器的意思,所以这块是设置什么条件下触发pipeline代码执行,以及触发的频率
cron
接受一个cron风格的字符串来定义Pipeline应重新触发的常规间隔,例如: triggers { cron(‘H 4/* 0 0 1-5’) }
####pollSCM
接受一个cron风格的字符串来定义Jenkins应该检查新的源更改的常规间隔。如果存在新的更改,则Pipeline将被重新触发。例如:triggers { pollSCM(‘H 4/* 0 0 1-5’) }
upstream
接受逗号分隔的作业字符串和阈值。 当字符串中的任何作业以最小阈值结束时,将重新触发pipeline。例如:triggers { upstream(upstreamProjects: ‘job1,job2’, threshold: hudson.model.Result.SUCCESS) }
举例一个可能利用scm的场景,如果一个公司做到了很好的代码覆盖测试,一般都会,如果监控到有人提交代码,就会自动化触发启动相关的单元测试。这个场景就是适合在pipeline代码里使用triggers指令,下面代码举例一个pollSCM的基本使用。
1 | pipeline { |
解释下“H H(9-16)/2 * * 1-5)”的含义,这个你可以在上面截图这个页面点击右侧这个问号,出来具体含义。第一步,先根据空格,把字符串切割成5段
所以,H H(9-16)/2 * * 1-5) 的含义就是:
第一部分“H” 表示hash,记住不是表示hour,是一个散列值,含义就是在一个小时之内,会执行一次,但是这次是一个散列值,而且不会并发执行。
第二部分“H(9-16)/2”,表示白天在早上9点到下午5点,每间隔2小时执行一次。
第三部分“*“,每天执行
第四部分“*“表示每月执行
第五部分“1-5“ 表示周一到周五执行
所以上面这个表达式“H H(9-16)/2 * * 1-5) “的含义就是,在每个月的周一到周五的白天,从早上9点到下午5点,每间隔两个小时去触发一次自动化构建。 这个就比较适合,我们每天上班,间隔两个小时去跑一次单元自动化测试。间隔时间长短,取决服务器压力和业务具体场景
input指令
该input指令允许在一个stage{…}显示提示输入等待。在inpt{…}写一些条件,然后用户触发构建这个job,但是这个时候没有接收到有效的input, job会一直在等待中;
下面解释input{…}里面支持写那些option。
message
必选,这个message会在用户提交构建的页面显示,提示用户提交相关的input条件
id
可选,可以作为这个input的标记符,默认的标记符是这个stage的名称
ok
可选, 主要是在ok按钮上显示一些文本,在input表单里
submitter
可选,里面可以写多个用户名称或者组名称,用逗号隔开。意思就是,只有这写名称的对应用户登陆jenkins,才能提交这个input动作,如果不写,默认是任何人都可以提交input。
parameters
可选,我们前面学的parameters没有区别,就是定义一些参数的地方
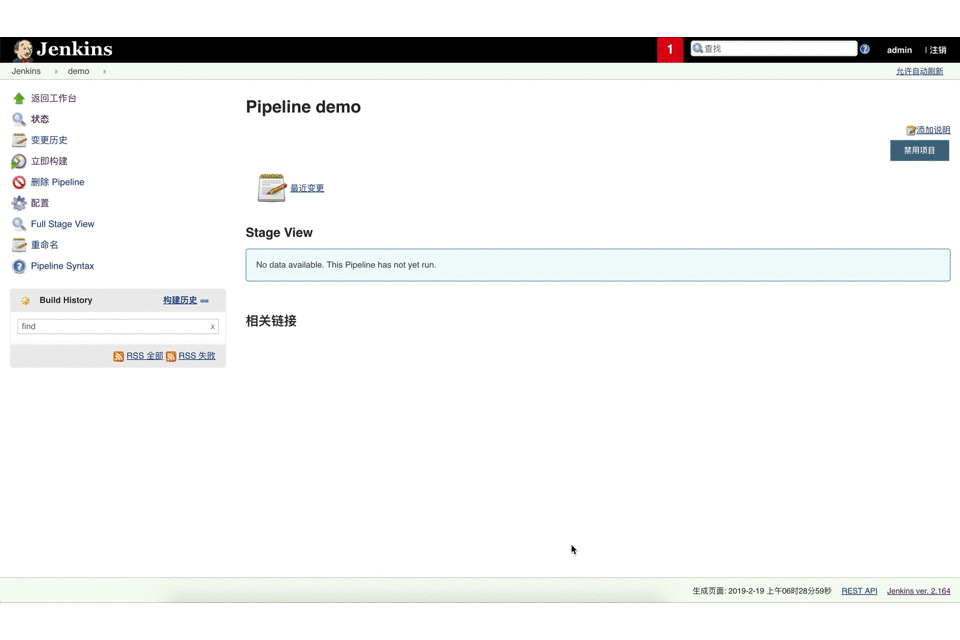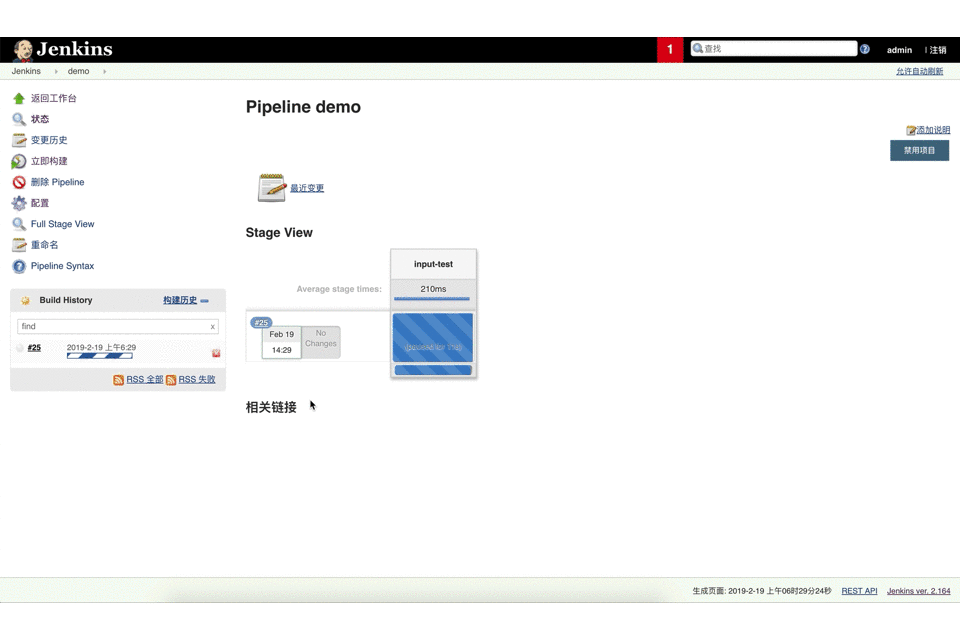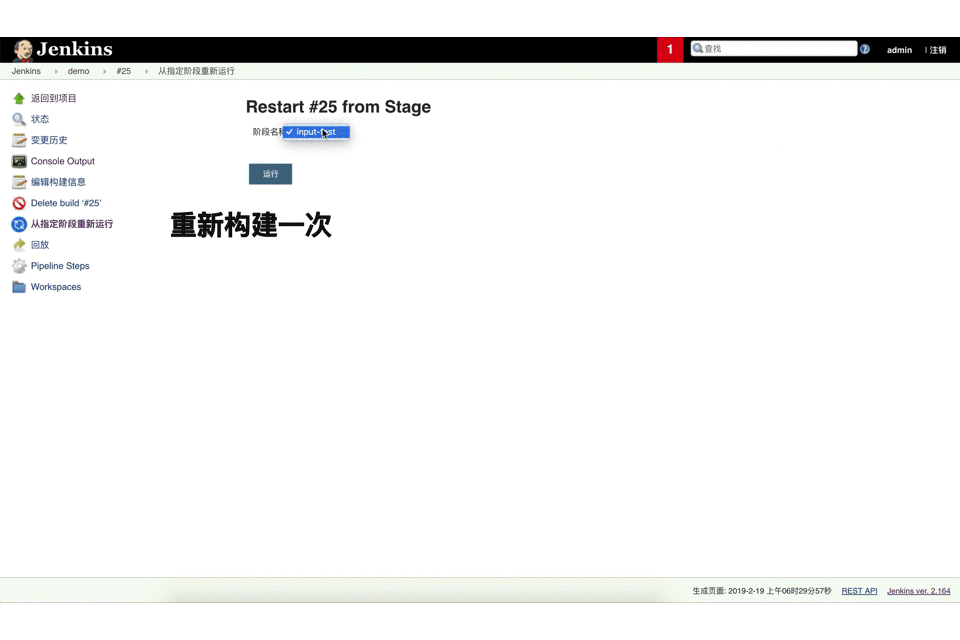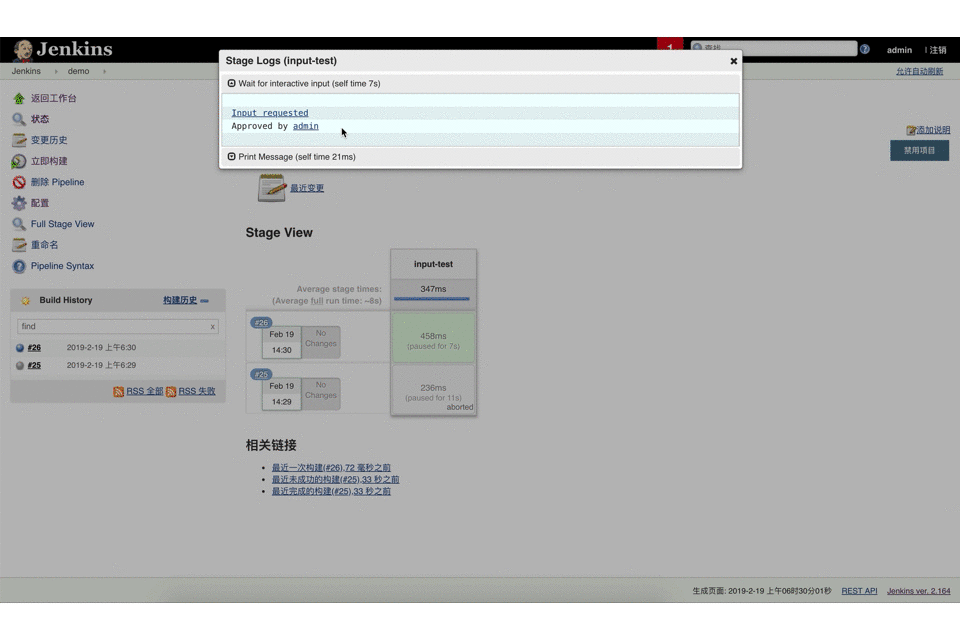
代码示例:
1 | pipeline { |
when指令
when指令允许流水线根据给定的条件决定是否应该执行阶段
when指令必须包含至少一个条件。
when 指令包含多个条件, 所有的子条件必须返回True,阶段才能执行
下面详细解释下when可以使用的内置条件
branch
当正在构建的分支与模式给定的分支匹配时,执行这个阶段;例如:when { branch 'master' }。请注意,这仅适用于多分支Pipeline。
environment
当指定的环境变量是给定的值时,执行这个步骤, 例如: when { environment name: 'DEPLOY_TO', value: 'production' }
expression
当指定的Groovy表达式评估为true时,执行这个阶段, 例如: when { expression { return params.DEBUG_BUILD } }
not
当嵌套条件是错误时,执行这个阶段,必须包含一个条件,例如: when { not { branch 'master' } }
allOf
当所有的嵌套条件都正确时,执行这个阶段,必须包含至少一个条件,例如: when { allOf { branch 'master'; environment name: 'DEPLOY_TO', value: 'production' } }
anyOf
当至少有一个嵌套条件为真时,执行这个阶段,必须包含至少一个条件,例如: when { anyOf { branch 'master'; branch 'staging' } }
在进入 stage的 agent前测试执行when
默认情况下, 如果定义了某个阶段的agent,在进入该stage的agent后该 stage的when 条件将会被执行。但是, 可以通过在 when块中指定beforeAgent 选项来更改此选项。如果beforeAgent 被设置为 true, 那么就会首先对when条件进行评估 , 并且只有在when条件验证为真时才会进入agent
1 | pipeline { |