[TOC]
变量在一定程度上能满足函数及代码要求。如果编写一些复杂算法、结构和逻辑,就需要更复杂的类型来实现。这类复杂类型一般情况下具有各种形式的存储和处理数据的功能,将它们称为“容器(container)”。
数组
数组(Array) 是一段固定长度的连续内存区域
在Go语言中,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化。
Go 的数组和切片都是从C语言延续过来的设计。
声明数组
1 | var 数组变量名 [元素数量]T |
其中:
- 数组变量名:数组声明及使用时的变量名
- 元素数量:数组的元素数量。可以是一个表达式,但最终通过编译期计算的结果必须是整形数值
- T 可以是任意基本类型,包括 T 为数组本身。但类型为数组本身时,可以实现多维数组
1 | var team [3] string |
数组初始化
数组可以在声明时使用初始化列表进行元素设置,参考下面的代码:
1 | var team = [3]string{"JD", "TaoBao", "Wechat"} |
这种方式编写时,需要保证大括号后面的元素数量与数组的大小一致
但一般情况下,这个过程可以交给编译器,让编译器在编译时,根据元素个数确定数组大小
1 | var team = [...]string{"JD" , "TaoBao" , "Wechat"} |
...表示让编译器确定数组大小。上面例子中,编译器会自动为这个数组设置元素个数为 3
遍历数组
遍历数组也和遍历切片类似
1 | var team = [...]string{"JD", "TaoBao", "Wechat"} |
切片
切片是一个拥有相同类型元素的可变长度的序列,Go语言切片的内部包含地址、大小、容量,切片一般用于快速地操作一块数据集合。如果将数据集合比作切糕的话,切片就是你要的“那一块”。切的过程包含从哪里开始(这个就是切片的地址)及切多大(这个就是切片的大小)。容量可以理解为装切片的口袋大小
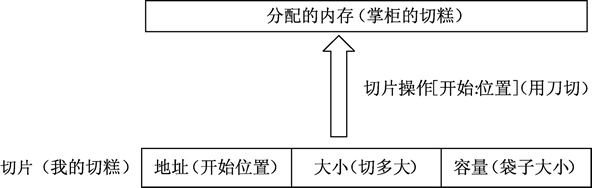
生成切片(从数组或切片生成新的切片)
切片默认指向一段连续内存区域,可以是数组,也可以是切片本身
从连续内存区域生成切片是常见的操作
1 | slice[开始位置:结束位置] |
- slice表示目标切片对象
- 开始位置对应目标切片对象的索引
- 结束位置对应目标切片的结束索引
从数组生成切片:
1 | var arr = [3]int{1,2,3} |
[2]就是arr[1:2]切片操作的结果
从数组或切片生成新的切片拥有如下特性:
- 取出的元素数量为:结束位置-开始位置。
- 取出元素不包含结束位置对应的索引,切片最后一个元素使用 slice[len(slice)] 获取。
- 当缺省开始位置时,表示从连续区域开头到结束位置。
- 当缺省结束位置时,表示从开始位置到整个连续区域末尾。
- 两者同时缺省时,与数组本身等效。
- 两者同时为0时,等效于空切片,一般用于切片复位。
根据索引位置取切片 slice 元素值时,取值范围是(0~len(slice)-1),超界会报运行时错误
生成切片时,结束位置可以填写 len(slice) 但不会报错。
具体,下面使用一些实例演示:
指定范围生成切片
1 | package main |
切片在指针的基础上增加了大小,约束了切片对应的内存区域,切片使用中无法对切片内部的地址和大小进行手动调整,因此切片比指针更安全、强大。
表示原有的切片
生成切片的格式中,当开始和结束都范围都被忽略,则生成的切片将表示和原切片一致的切片,并且生成的切片与原切片在数据内容上是一致的
1 | package main |
重置切片,清空所有元素
1 | package main |
声明新的切片
除了可以从原有的数组或者切片中生成切片,你也可以声明一个新的切片
每一种类型都可以拥有其切片类型,表示多个类型元素的连续集合。因此切片类型也可以被声明。切片类型声明格式如下:
1 | var name []T |
- Name 表示切片的变量名
- T 表示切片对应的元素类型
1 | package main |
切片是动态结构,只能与nil判定相等,不能互相判等时。
声明新的切片后,可以使用 append()函数来添加元素。
使用make()函数构造切片
如果需要动态的创建一个切片,可以使用make()内建函数
1 | make([]T,size,cap) |
- T : 切片的元素类型
- size : 就是为这个类型分配多少个元素
- cap : 预分配元素数量,这个值设定不影响size,只是能提前分配空间,降低多次分配空间造成的性能问题。
示例如下:
1 | package main |
a 和 b 均是预分配 2 个元素的切片,只是 b 的内部存储空间已经分配了 10 个,但实际使用了 2 个元素。
容量不会影响当前的元素个数,因此 a 和 b 取 len 都是 2。
使用 make() 函数生成的切片一定发生了内存分配操作。但给定开始与结束位置(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存区域,设定开始与结束位置,不会发生内存分配操作。
切片不一定必须经过 make() 函数才能使用。生成切片、声明后使用 append() 函数均可以正常使用切片
使用append()为切片添加元素
- Go语言的内建函数 append() 可以为切片动态添加元素
- 每个切片会指向一片内存空间,这片空间能容纳一定数量的元素
- 当空间不能容纳足够多的元素时,切片就会进行“扩容”。“扩容”操作往往发生在 append() 函数调用时
- 切片在扩容时,容量的扩展规律按容量的 2 倍数扩充,例如 1、2、4、8、16……
1 | package main |
append() 函数除了添加一个元素外,也可以一次性添加很多元素。
1 | package main |
第 13 行,在newCompany后面加上了
...,表示将 newCompany 整个添加到 car 的后面。
切片复制
使用内建的 copy() 函数,可以迅速地将一个切片的数据复制到另外一个切片空间中,copy() 函数的使用格式如下:
1 | copy(originSlice,srcSlice []T)int |
- originSlice 为数据来源切片
- srcSlice为复制的目标。目标切片必须分配过空间且足够承载复制的元素个数,来源和目标的类型一致,copy 的返回值表示实际发生复制的元素个数。
删除切片元素
Go语言并没有对删除切片元素提供专用的语法或者接口,需要使用切片本身的特性来删除元素
1 | seq := []string{"a", "b", "c", "d", "e"} |
代码的删除过程可以使用下图来描述。
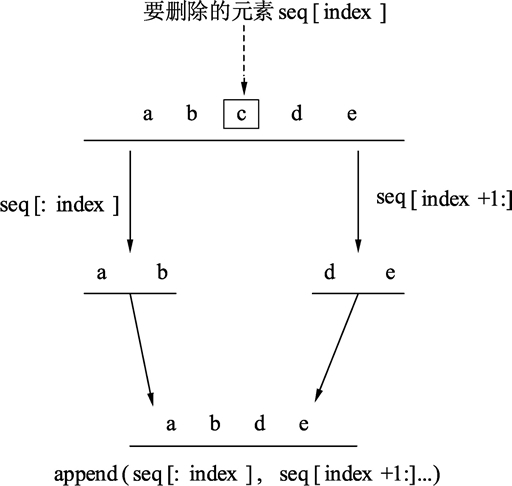
Go 语言中切片删除元素的本质是:以被删除元素为分界点,将前后两个部分的内存重新连接起来。
连续容器的元素删除无论是在任何语言中,都要将删除点前后的元素移动到新的位置。随着元素的增加,这个过程将会变得极为耗时。因此,当业务需要大量、频繁地从一个切片中删除元素时,如果对性能要求较高,就需要反思是否需要更换其他的容器(如双链表等能快速从删除点删除元素)。
map(Go语言映射)
在业务和算法中需要使用任意类型的关联关系时,就需要使用到映射,如学号和学生的对应、名字与档案的对应等。
Go语言提供的映射关系容器为 map,map使用散列表(hash)实现。
添加数据到map
Go语言中 map 的定义是这样的:
1 | map[keyType]vluesType |
- keyTyp 表示键类型
- valueType 表示键对应值类型
一个map 里,符合keyType和valueType 的映射总是成对出现
1 | package main |
尝试查找一个不存在的键,那么返回的将是 ValueType 的默认值
某些情况下,需要明确知道查询中某个键是否在 map 中存在,可以使用一种特殊的写法来实现
1 | v, ok := scene["route"] |
在默认获取键值的基础上,多取了一个变量 ok,可以判断键 route 是否存在于 map 中。
map 还可以在声明时填充内容,例如:
1 | m := map[string]string{ |
遍历map
遍历key 和 value
map 的遍历过程使用 for range循环完成,代码如下:
1 | family := map[string]string{ |
只遍历value
遍历时,可以同时获得键和值。如只遍历值,可以使用下面的形式:
1 | for _,value := range family{ |
将不需要的键改为匿名变量形式。
只遍历key
只遍历键时,使用下面的形式:
1 | for key := range family{ |
无须将值改为匿名变量形式,忽略值即可
map 元素删除和清空
元素删除
使用delete()内建函数从map中删除一组键值对 ,delete()函数的格式如下
1 | delete(map , 键) |
- map 为要删除的map实例
- 键为要删除的 map 键值对中的键
1 | numMap := make(map[string]int) |
清空map
有意思的是,Go语言中并没有为 map 提供任何清空所有元素的函数、方法。清空 map 的唯一办法就是重新 make 一个新的 map。不用担心垃圾回收的效率,Go 语言中的并行垃圾回收效率比写一个清空函数高效多了。
sync.Map(在并发环境中使用的map)
Go 语言中的 map 在并发情况下,只读是线程安全的,同时读写线程不安全。
1 | // 创建一个int到int的映射 |
运行代码会报错,输出如下:fatal error: concurrent map read and map write
运行时输出提示:并发的 map 读写。也就是说使用了两个并发函数不断地对 map 进行读和写而发生了竞态问题。map 内部会对这种并发操作进行检查并提前发现
需要并发读写时,一般的做法是加锁,但这样性能并不高。Go 语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map。sync.Map 和 map 不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构。
sync.Map有以下特性:
- 无须初始化,直接声明即可。
- sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用。Store 表示存储,Load 表示获取,Delete 表示删除。
- 使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值。Range 参数中的回调函数的返回值功能是:需要继续迭代遍历时,返回 true;终止迭代遍历时,返回 false。
并发安全的 sync.Map 演示代码如下:
1 | var scenes sync.Map |
sync.Map 没有提供获取 map 数量的方法,替代方法是获取时遍历自行计算数量。sync.Map 为了保证并发安全有一些性能损失,因此在非并发情况下,使用 map 相比使用 sync.Map 会有更好的性能。
list(列表)
列表是一种非连续存储的容器,由多个节点组成,节点通过一些变量记录彼此之前的关系。列表有多种实现方法,如单链表、双链表等。
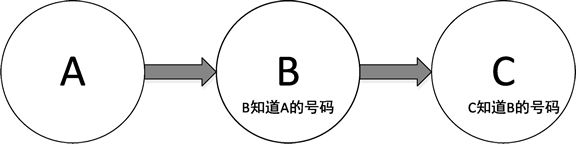
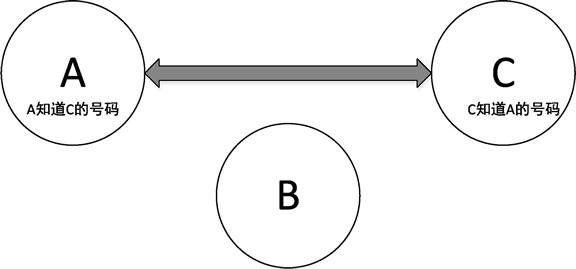
列表的原理可以这样理解:假设 A、B、C 三个人都有电话号码,如果 A 把号码告诉给 B,B 把号码告诉给 C,这个过程就建立了一个单链表结构,如下图所示:
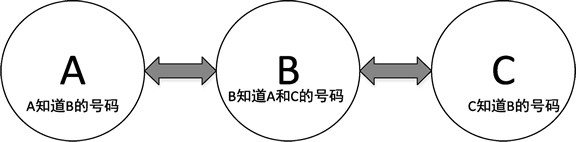
如果在这个基础上,再从 C 开始将自己的号码给自己知道号码的人,这样就形成了双链表结构,如下图所示。
那么如果需要获得所有人的号码,只需要从 A 或者 C 开始,要求他们将自己的号码发出来,然后再通知下一个人如此循环。这个过程就是列表遍历。
如果 B 换号码了,他需要通知 A 和 C,将自己的号码移除。这个过程就是列表元素的删除操作,如下图所示
在Go语言中,将列表使用 container/list 包来实现,内部的实现原理是双链表。列表能够高效地进行任意位置的元素插入和删除操作。
初始化列表
list 的初始化有两种方法:New 和声明。两种方法的初始化效果都是一致的。
通过container/list 包的 New 方法初始化 list
1 | 变量名 := list.New() |
通过声明初始化list
1 | var 变量名 list.List |
列表与切片和 map 不同的是,列表并没有具体元素类型的限制。因此,列表的元素可以是任意类型。这既带来便利,也会引来一些问题。给一个列表放入了非期望类型的值,在取出值后,将 interface{} 转换为期望类型时将会发生宕机。
在列表中插入元素
双链表支持从队列前方或后方插入元素,分别对应的方法是 PushFront 和 PushBack。
这两个方法都会返回一个 *list.Element 结构。如果在以后的使用中需要删除插入的元素,则只能通过 *list.Element 配合Remove()方法进行删除,这种方法可以让删除更加效率化,也是双链表特性之一
下面代码展示给list添加元素:
1 | l := list.New() |
列表插入元素的方法如下表所示。
| 方 法 | 功 能 |
|---|---|
| InsertAfter(v interface {}, mark * Element) * Element | 在 mark 点之后插入元素,mark 点由其他插入函数提供 |
| InsertBefore(v interface {}, mark * Element) *Element | 在 mark 点之前插入元素,mark 点由其他插入函数提供 |
| PushBackList(other *List) | 添加 other 列表元素到尾部 |
| PushFrontList(other *List) | 添加 other 列表元素到头部 |
从列表中删除元素
列表的插入函数的返回值会提供一个 *list.Element 结构,这个结构记录着列表元素的值及和其他节点之间的关系等信息。从列表中删除元素时,需要用到这个结构进行快速删除。
1 | l := list.New() |
下表中展示了每次操作后列表的实际元素情况。
| 操作内容 | 列表元素 |
|---|---|
| l.PushBack(“age”) | age |
| l.PushFront(“18+”) | 18+, age |
| element := l.PushBack(“fist”) | 18+, age, fist |
| l.InsertAfter(“high”, element) | 18+, age, fist, high |
| l.InsertBefore(“noon”, element) | 18+, age, noon, fist, high |
| l.Remove(element) | 18+, age, noon, high |
遍历列表
遍历双链表需要配合 Front()函数获取头元素,遍历时只要元素不为空就可以继续进行。每一次遍历调用元素的 Next,如代码中第 6 行所示
1 | l := list.New() |
使用 for 语句进行遍历,其中 i:=l.Front() 表示初始赋值,只会在一开始执行一次;每次循环会进行一次 i!=nil 语句判断,如果返回 false,表示退出循环,反之则会执行 i=i.Next()。